Issuu.com est une plateforme de partage de livre virtuel, avec un simple PDF vous aller pouvoir créer un livre virtuel.
C’est génial de pouvoir naviguer à travers des milliers de livre et documents sur Issuu, mais comment faire pour télécharger le PDF générer par Issuu ?
Et bien c’est assez simple, bon en fait pas tout à fait, chaque pages du livre virtuel est une image qui est stocké sur le serveur. Pour récuperer toutes ces pages j’utilise un script en Ruby. Voici la méthode :
- Tout d’abord télécharger Ruby et installer le sur votre pc ou mac pour pouvoir exécuter le script (disponible sur Windows, Linux et Mac).
- Ensuite rendez vous sur l’adresse du document que vous voulez récuperer, par exemple : http://issuu.com/zooma/docs/migration_ooo_framabook
- Une fois sur votre livre virtuel afficher la source de la page web (Affichage > Afficher la source, ou généralement CTRL+U)
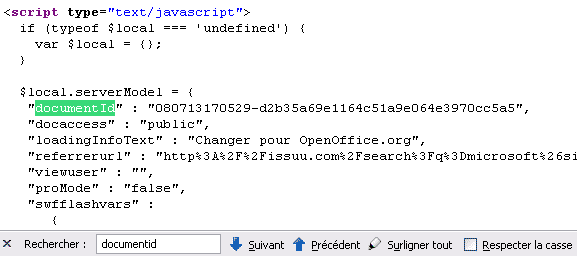
- Dans cette source recherche le terme suivant : « documentId »
- Copier l’ID, il vous servira pour le script
- Puis noter le nombre de pages
Maintenant sur votre pc, ouvrer notepad (avec notepad++ c’est mieux ^_^) et copier le script suivant :
[ruby]#————————————————-# issuu.rb – récuperer tous les jpg d’un document
#————————————————-
# 1. Ouvrir votre document sur issuu.co, comme d’habitude
# par exemple : http://issuu.com/zooma/docs/migration_ooo_framabook
# 2. Notez le nombre de page que comporte le document ; configurer la variable $PAGES
# 3. Depuis le menu de votre navigateur, cliquer sur Affichage > Source
# 4. Dans votre document chercher le texte "documentId"
# 5. Copier la valeur "081230122554-f76b0df1e7464a149caf5158813252d9"
# sur la variable $PUB
# 6. Exécuter le script:
# issuu.rb
require ‘open-uri’
$PUB="081230122554-f76b0df1e7464a149caf5158813252d9"
$PAGES=20
for $X in 1..$PAGES do
$PX="page_#{$X}.jpg"
$PADX="page_#{"%03d" % $X}.jpg"
puts(Time.now.strftime(‘%Y-%m-%d %X’) +" get "+ $PX +">>"+ $PADX)
open($PADX,"wb").write(open("http://image.issuu.com/#{$PUB}/jpg/#{$PX}").read)
end
puts("#{Time.now.strftime(‘%Y-%m-%d %X’)} DONE")
[/ruby]
Il y a deux variables à changer :
- $PUB : ici il faut copier l’ID que vous avez récupérer dans la source du livre numérique
- $PAGES : ici c’est le nombre de pages qu’il faut mettre
Une fois le script modifié enregistré le avec l’extention .rb (Ruby Script)
Déplacer votre script Ruby dans un dossier, car toutes les images seront importées à l’endroit ou est placé le script.
Vous pouvez maintenant exécuter le script en double cliquant dessus, une fenêtre DOS va s’ouvrir avec le décompte de chaque pages qui se copie dans le répertoire de votre script.

Vous retrouverez donc autant de fichier JPG que de pages, chaque fichier étant l’image de la page. Pas évident de lire votre livre comme ça.. du coup on va le relier, en compilant toutes les images en un PDF.
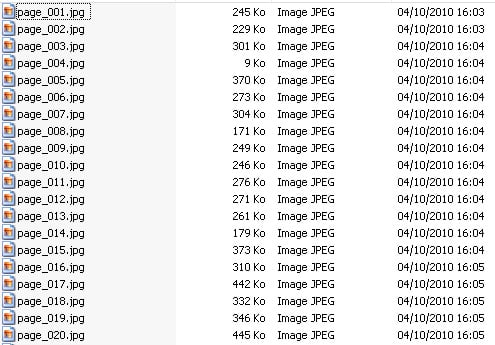
Pour ça utilisé par exemple le programme libre PDF-XChange Viewer (disponible sur votre LiberKey) qui vous permettra de transformer toutes les images en un seul PDF, il en existe certainement d’autres…
Et pour aller encore plus loin, vous pouvez utiliser un logiciel OCR pour pouvoir modifier le PDF.
Et si vous souhaitez récupérer seulement une ou deux pages vous pouvez utilisé ce script.
Ou ce script (a copié en tant que bookmark ):
[ruby]javascript:function PadDigits(n,tD){n=n.toString();var pd= »;if(tD>n.length){for(var i=0;i<(tD-n.length);i++){pd+=’0′;}}return pd+n.toString();}void(window.stop());var id=/documentId(\W)*([\w-]+)/.exec(document.getElementsByTagName(‘html’)[0].innerHTML)[2];var np=prompt(‘Number of total pages to download\nDigits only!’);var lnk="";for(var i=1;i<=np;i++)lnk+='<a href="http://image.issuu.com/’+id+’/jpg/page_’+i+’.jpg">’+document.getElementsByTagName(‘title’)[0].innerHTML+’_’+PadDigits(i,np.toString().length)+'</a><br>’;void(document.body.innerHTML=lnk);[/ruby]En espérant que cela puisse en aider certains…

Bonjour, je vous remercie pour ce tuto, je voulais savoir si il était possible d’agir sur la qualité des images téléchargées ?
merci encire
Super conseils! Ca m’a pris un peu de temps pour réussir, mais c’était bien expliqué, c’est juste que je ne possédais pas trop ces concepts encore. Qualité des images moyenne, mais c’est lisible.Merci.RAA
Bonjour,
Auriez-vous trouvé un moyen de convertir les fichiez SWF en PDF?? C’est urgent, et ça fait déjà 2 jours que je cherche une solution mais en vain… 🙁
Merci.
Bonjour, je n’arrives pas à executer mon fichier .RB, la page s’ouvre une seconde et se referme automatiquement… que faire??????
J’ai exactement le même problème, qqu aurait une solution?
Il est préférable de changer les » ‘ » comme ci-dessous sous ruby 2.0 pour que cela fonctionne.
Je remercie Mickaël Guillerm pour ce script RUBY
#————————————————-
# issuu.rb – récuperer tous les jpg d’un document
#————————————————-
# 1. Ouvrir votre document sur issuu.co, comme d’habitude
# par exemple : http://issuu.com/zooma/docs/migration_ooo_framabook
# 2. Notez le nombre de page que comporte le document ; configurer la variable $PAGES
# 3. Depuis le menu de votre navigateur, cliquer sur Affichage > Source
# 4. Dans votre document chercher le texte « documentId »
# 5. Copier la valeur « 081230122554-f76b0df1e7464a149caf5158813252d9 »
# sur la variable $PUB
# 6. Exécuter le script:
# issuu.rb
require « open-uri »
$PUB= »140611221600-802ec76d093eadc9406783ee35e5809d »
$PAGES=43
for $X in 1..$PAGES do
$PX= »page_#{$X}.jpg »
$PADX= »page_#{« %03d » % $X}.jpg »
puts(Time.now.strftime(« %Y-%m-%d %X ») + » get « + $PX + »>> »+ $PADX)
open($PADX, »wb »).write(open(« http://image.issuu.com/#{$PUB}/jpg/#{$PX} »).read)
end
puts(« #{Time.now.strftime(« %Y-%m-%d %X »)} DONE »)